
Approaches for Moving Data In a Network
There are basically two approaches for moving data from Source host to the Destination Host. These are:
1. Circuit Switching
2. Packet Switching
CIRCUIT SWITCHING
Now I should give a live example that will make circuit switching clear to you.
Let us suppose that there are 2 restaurants A and B. In restaurant A, there is a need to reserve a table before going there for dinner or lunch. Whereas in restaurant B, there is no need for reservation. Now before going to restaurant A, you have to make a call and reserve a table but when you will arrive there, the table is set for you and you can directly be seated and order your meal. But in restaurant B, you need not bother to reserve a table, but when you arrive at the restaurant, you might have to wait for a table to get free before you can be seated.
In this restaurant analogy, restaurant A uses circuit switching for the customers.

A very classic example of circuit switching is your Landlines or telephones. When you make a call to your friend, a connection is established between both of you. And this connection remains open till the time you both are contacting and don't put your phone down. Since all the resources are reserved by you for that network, you can send and receive data at a very constant transmission rate.
Circuit Switched Networks are used for voice and video calls where any delay in the call can make a huge difference. Another example of circuit switched networks is Skype, for video calling.
Advantages of Circuit Switched Networks
1. Dedicated connection is established, the delays in the communication are very less or almost nil.
2. The quality of the connection or the call is very high.
Disadvantages of Circuit Switched Networks
1. Now say, on telephone you talk to your friend for 15 min. But
between these 15 min. , you remain quiet for 5 min., while still holding
the phone in your hand. Thus, for those 5 min., the resources are
misused and get wasted.
2. It is not a good option for networks, where the traffic is
very high. Because if two hosts reserve the resources, the other hosts
have to wait for that period to leave those resources. Resulting in huge
delays. In simple words, we can say that, circuit switching is not suitable for bursty traffic networks.
- For circuit switched networks, there are various multiplexing techniques that are being used, in order to increase bandwidth utilisation. I will tell you about the different multiplexing techniques in the later posts.
PACKET SWITCHING
In Packet Switching, instead of reserving the resources, the packets are
being send on the demand phenomenon. For example, if a host A has to
send a packet to host B through a communication link or router, but that
link is over-flow or is full, then the packet has to wait in the queue,
to get transmitted.
Packet Switching is a dynamic phenomenon, that uses the resources only when needed.

Advantages of Packet Switching
The resources or the bandwidth is optimally utilised without any wastage.
Disadvantages of Packet Switching
1.The packets can arrive in a wrong order as they were sent.
2. The delays between different packet can be different, resulting in degradation of the service provided.
Therefore, it all depends on the Application Developer, which
Switching technique he wants to use. In today's Internet, as the Traffic
is so huge, so Packet Switching is used in Internet Services.








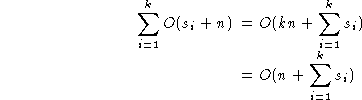
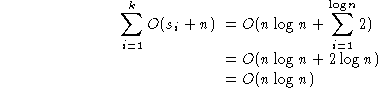 .
.