
KNAPSACK PROBLEM
JUNE 2014 - PAPER III Q.No 62
62. Consider the fractional knapsack instance n=4, (p1,p2,p3,p4) = (10,10,12,18)(w1,w2,w3,w4)=(2,4,6,9) and M=15. The maximum profit is given by,
(Assume p and w denotes profit and weights of objects respectively).
(A)40
(B)38
(C)32
(D)30
Ans:-B
Explanation:-
Knapsack problem can be solved either using Greedy approach or through Dynamic programming. I am going to be explaining using the former. It has been proved that for the knapsack problem using greedy method we always get the optimal solution provided the objects are arranged in decreasing order of pi/wi. So, before solving the problem, let us arrange all the objects in decreasing order of pi/wi.
Capacity of the knapsack M = 15
Number of objects = 4
Profits(p1,p2,p3,p4)=(10,10,12,18)
Weights(w1,w2,w3,w4)=(2,4,6,9)
To get the solution arrange objects in decreasing order of profit/weights as shown below.
p1/w1=10/2 =5
p2/w2=10/4=2.5
p3/w3=12/6=2
p4/w4=18/9=2
Arrange in decreasing order of pi/wi, we get
| Object | Weight | Profit | Pi/wi |
|---|---|---|---|
| 1 | 2 | 10 | 5 |
| 2 | 4 | 10 | 2.5 |
| 3 | 6 | 12 | 2 |
| 4 | 9 | 18 | 2 |
The fractions of the objects selected and the profit we get can be computed as shown below:
| Remaining Capacity | Object selected | Weight of the object | Fraction of the object selected |
|---|---|---|---|
| 15 | 1 | 2 | 1 full unit |
| 15-2=13 | 2 | 4 | 1 full unit |
| 13-4=9 | 3 | 6 | 1 full unit |
| 9-6=3 | 4 | 9 | 3/9 or 1/3 fraction of unit |
So, the solution vector will be=(1,1,1,1/3)
Profits=1 X 10 + 1 X 10 + 1 X 12 + 1/3 X 18
Profits=10+10+12+6
Profits=20+18
=38
So the correct answer will be 38. The maximum profit is given by option (B) which is 38. Solve the following problem and see.
I. Obtain the optimal solution for the knapsack problem given the following: M=40,n=3, (p1,p2,p3)=(30,40,35) and (w1,w2,w3)=(20,25,10).
. The answer for the above problem is 82.5

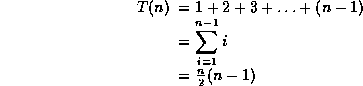
 .
.




























 time, where
time, where  and
and  are the number of vertices and edges respectively.
are the number of vertices and edges respectively.






 for explicit graphs traversed without repetition,
for explicit graphs traversed without repetition,  for implicit graphs with branching factor b searched to depth d
for implicit graphs with branching factor b searched to depth d Binary Search Tree
Binary Search Tree


