HTTP Types and Its Message Format
In this post, I am going to tell you about the types of HTTP connections and HTTP message format.
First we will start with the HTTP connection types. There are basically two types of HTTP connections: Persistent and Non-Persistent. Lets have a look at each one of them.
When you or any host communicate
with the server, there is a long series of request-response messages,
that is being exchanged between you and the server. Therefore, depending
on the type of application, the Application developer has to make a
decision, that should all the request-response messages should be sent
over a single TCP connection or they should be sent under individual TCP
connection for every pair of request-response message.
If all the request-response message pair are sent over different TCP connection, it is known as Non-Persistent Connections and if there is only one TCP connection for a series of messages, it is known as Persistent Connection.
Hyper Text Transfer Protocol (HTTP) with non-persistent connection :
Let me start by giving you an example that will make you understand
about HTTP non-persistent connection. The transfer of a Web Page from
server to client under non-persistent connection is as follows:
Let us suppose that a web page consists of a base HTML file and 20 PNG
images, all these 21 files reside on the same server. Say, the address
or the URL of the base HTML file is
http://www.com2networks.blogspot.com/department/images.html.
Now the process starts.
1. The HTTP client process initiates a TCP connection to the server
www.com2networks.blogspot.com on port number 80, the default port number
for HTTP. There will be a socket at the client and a socket at the
server associated with the TCP connection
2. The HTTP client sends an HTTP request message to the server via its socket. The request message includes the path name /department/images.html.
3. The HTTP server process receives the request message via its socket,
retrieves the object /department/images.html from its storage,
encapsulates or embed the object in an HTTP response message, and sends
the response message to the client via its socket.
4. The HTTP server process tells TCP to close the TCP connection.
5. The HTTP client receives the response message. The TCP connection
terminates. The message indicates that the encapsulated object is an
HTML file. The client extracts the file from the response message,
examines the HTML file and finds references to the 20 PNG objects.
6. Now to get those 20 PNG images, the first four steps are again repeated.
The steps above explains you the use of non-persistent connections,
where each TCP connection is closed after the server sends the
object—the connection does not persist or remains for other objects.
Each TCP connection transports only one request message and one response
message. Therefore in this case, when a user requests the Web page, 21
TCP connections must be generated.
Lets now see into the depth of non-persistent connection and calculate
the time taken from requesting a web page and till the entire file is
received.
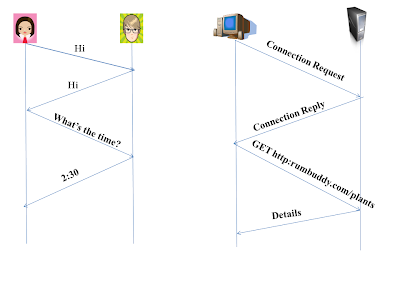
Here I will describe you the time taken by a small packet to travel from client to server and back to client. This is known as Round-Trip Time (RTT). The RTT includes the packet propagation delay, queuing delay at the router and switches and the the processing delay.
What happens when you click on a link or a hyperlink , the client or
your browser initiates a TCP connection with the server. This connection
involves 3 steps that are often called as "3-way handshake". This handshake includes, (a) The client sends a TCP segment to the server, (b) The server acknowledges and responds with a TCP segment, and finally (c) The client acknowledges back to the server.
The 1st two parts (a) and (b) takes 1 RTT. After completing the 1st two
steps , the client sends a request message along with the 3rd part of
handshake i.e. acknowledgement to server. After receiving the request
message and acknowledgement , the server respond by sending the HTML
file into the TCP connection. This HTTP request-response takes 1 RTT. So
approximately, we can say that, Total response time taken is 2 RTT's
plus the transmission time taken by the server. Now as usual, I will
clear it by drawing a figure for you.

Figure: TIME TAKEN IN TRANSMISSION OF A HTML FILE
Hyper Text Transfer Protocol (HTTP) with persistent connection :
As we can clearly see that , non-persistent connections have certain
disadvantages. For every requesting object, you have to set-up a new TCP
connection that is a huge overhead for a server that is serving
millions of requests. And also, it will take 2 RTT for every requested
object.
To overcome theses issues, HTTP is used with persistent connections. In
persistent connection, the server doesn't close the connection after
sending a response. More than one request and response can be sent
between the same client and the same server over the same TCP
connection. The example we have taken above of an HTML file and 20 PNG
images. So these 21 objects can be sent over a single persistent
connection.The request for different objects are made simultaneously
without waiting for the replies to the pending requests. This phenomenon
is often called as pipelining. When the server receives back-to-back
requests, it sends the objects back-to-back. The server closes the
connection , when the connection remains useless or idle for a
particular time period.
- The default mode of HTTP uses persistent connections. However an application developer can modify it to non-persistent according to his need.
Now lets move on and have a look at the types of HTTP message formats.
As you already know, there are two types of HTTP message. One is Request
message and the other is the Response message.
HTTP REQUEST MESSAGE
GET /department/images.html HTTP/1.1Host : www.com2networks.blogspot.com
Connection : close
User-agent : Chrome/7.0
Language : Fr
Have a look at this message and try to understand it. You can see that the message is written in ASCII text, so that an ordinary human being can read it. As this request message contains 5 lines. Similarly a request message can have more lines and as few as 1 line also.
In this example, the 1st line of the message is said to be the request line and the further are called the header lines.
Request line: It has 3 fields: (a) Method field, (b) URL field and (c) HTTP version field.
There are various methods that can be there in a method field such as GET, POST, PUT, HEAD, DELETE.
GET: The GET method is used for general web page request.
POST: The POST method is used to ad parameters to the server.
The URL field contains the address of the requested object. As here, it is /department/images.html.
Version field: Version of the HTTP that browser implements, here it is version HTTP/1.1.
Now the header fields.
1st header field contains the host i.e. www.com2networks.blogspot.com, tells the name of the host on which the objects reside.
2nd header field Connection:close , browser tells the server that it doesn't want to bother with persistent connection. It wants server to close the connection after sending the requested object.
3rd header field User-agent : Chrome/7.0, a chrome browser. This field is useful in the cases where the server has different copies of the files for different version of user agent.
4th header field Language: Fr. It tells the server in which language , the desired copy of the requested file is wanted. Here it is French. If the server has the requested copy, it will send that, but if it doesn't , then it will response with the default version.
Now let me give you a general format of HTTP request message.

HTTP RESPONSE MESSAGE
HTTP/1.1 200 OK
Connection: close
Date: Fri, 06 Sept 2013 11:45:07 (GMT +05:30)
Server: Apache/2.2.3
Last-Modified: Sun, 01 Sept 2013 15:11:03 (GMT+05:30)
Content-Length: 4951
Content-Type: text/html
(data data data data data ...)
Have a look at this message and try to understand this. It basically has 3 sections. 1. An initial status line 2. Header lines 3. Entity body.
1. Status Line: It has 3 fields. (a) The protocol version. (b) A status code. (c) Status message
In the given message, the server is using HTTP/1.1 version and the code is 200 , that means everything is OK and executed properly (The server has found the object and sending it).
- Some common Status Code that you will generally get as response from the server, while requesting for a Web page are:
(i) 200 OK : It means , The Request succeed and the requested information has been sent.
(ii) 301 Moved permanently : It indicate that the requested URL has been permanently moved to a new address. This new URL will be indicated in the Location, header of the response message.
(iii) 400 Bad Request : When server doesn't understand the request, it shows this code.
(iv) 404 Not Found : The requested information doesn't exist on this server.
2. Now the header fields.
1st header field Connection : close, The server wants to inform the client that it is going to close the connection after sending the object.
2nd header field DATE : It indicated the time and the date when the HTTP response was sent by the server.
3rd header field Server : The name of the server used to generate the response message.
4th header field Last-Modified : Its the time and the date when the object was last created or modified.
5th header field Content-Length : It tells about the number of bytes in the response message that are being sent.
6th header field Content Type : It tells that the object in the entity body is a HTML text.
3. Entity body that is being denoted by data data data data....... is the meat of the message . It contains the requested object.
Let me give you a general format of HTTP response message.