Simple Mail Transfer Protocol (SMTP)
Introduction to Electronic Mail (E-Mail)
Electronic Mail or E-Mail has been among the most favorite Applications on the Internet for several years. It has become more and more powerful and secure over the years. It has been widely used throughout the Globe.
E-Mail is a asynchronous service i.e. you can send and read when it is convenient for you. You doesn't need to coordinate with other's schedule. Now a days, E-Mail has become so powerful that you can attach photos, videos, HTML files or any format file and send it.
An Internet Mail System has basically 3 components. 1. User-Agent. 2. Mail Server 3. Simple Mail Transfer protocol(SMTP). This Diagram will give you a overlook, how a mail system works.

Now we will discuss all the above 3 components. To describe these, I will take a Sender , James, who is sending the E-Mail, to a receiver, Steve.
If we want to read, send reply or retrieve an E-Mail, we do all this with the help of a user-agent. For Example, Microsoft-Outlook is a user-agent for Email. After
James is done with writing the mail,, his user-agent sends the message
to his mail server. In the mail server, the mail is stored in the mail
server's outgoing queue. When Steve wants to read that mail, his
user-agent retrieves the mail from his mailbox in his mail server.
Every recipient has a mailbox located in the mail servers. A mail starts from a user-agent travels to the sender's mail server, after that message reaches the receiver mail server, where it is stored in the receiver mailbox. Now Steve comes to read the mail in his mailbox. Thus, the mail server containing his mailbox will authenticate the Steve with his username and password.
Mail Servers are core item in a Email structure. James mail server must take care of the failure in Steve mail server. If the sender mail server is unable to send the mail, then it holds the mail in its queue and will attempt to deliver the message later. The reattempts to send a message are mostly done every 30 or 40 min. But if the message is not sent for few days, then the mail server removes it from the mailbox and informs the sender with an e-mail.
Introduction to Simple Mail transfer Protocol (SMTP)
SMTP is used to transfer mail from sender's mail server to the
recipient's mail server. Along with the number of advantages of SMTP,
there is also a disadvantage or you can say , an old-fashioned
characteristics of SMTP. The message sent in a SMTP mail, should
necessarily be in 7-bit ASCII format. This is the restriction that SMTP
apply on the mails. In today's world of Multimedia where a large number
of Photos and videos are being sent over mail, 7-bit ASCII is a pain.
Thus, before sending a binary coded multimedia data over SMTP, it has to
be converted into 7-bit ASCII and on the receiver side, it has to be
decoded back to binary after its Transport.
James sending mail to Steve. Lets have a look:
1. Now James opens his user-agent to
send a e-mail. He provides Steve e-mail address, writes or composes a
message and tells the user agent to send the message (by clicking on the
send button).
2. James user-agent send this mail to James' mail server, where the message gets placed into the message queue.
3. The SMTP client side, that is
running on the James mail server, see the message in the queue. Then it
opens a TCP connection with the SMTP server, that is running on Steve
mail server.
4. After the handshaking process, the SMTP client sends the message into the TCP connection.
5. The SMTP server side receives this message. Steve's mail server then places this mail in his mailbox.
6. Then Steve according to his convenience opens his user-agent, authenticates himself to the mail server and reads the mail.
Let me describe these 6 steps with the help of a figure:

A very enchanting feature of SMTP is
that SMTP doesn't store the mail in any intermediate mail server. For
example: If a James mail server is located in India and Steve's server
is located in USA, then the TCP connection will be directly between
India and USA servers. No intermediate server will be there. You can say
that, if Steve server is down, the message will remain in James mail
server and waits for the next attempt.
A general message that is being sent through SMTP is as follows:
Suppose server(S) name is India.com and client(C) name is USA.com.
S : 220 India.com
C : HELO USA.com
S : 250 Hello USA.com, Nice to meet you.
C : MAIL FROM:<James@USA.com>
S : 250 James@USA.com.... Sender OK.
C : RCPT TO:<Steve@India.com>
S : 250 Steve@India.com... Recipient OK.
C : DATA
S : 354 Enter Mail, end with "." on a line by itself.
C : Do you have a Grammar Book?
C : What about Atlas?
C : .
S : 250 Message accepted for delivery.
C : QUIT
S: 221 India.com closing connection.
The SMTP uses a persistent connection. Therefore simultaneous message
are being over the same connection. Like, the Client send the "Do you
have a Grammar Book?" and the "What about Atlas? , together on the same
TCP connection.
You can try the above script in the "Command prompt" of your system.
Before starting, give a command, <telnet servername 25>
Here sever name is the name of your local mail server. And 25 is the
default port number for SMTP. With this command , you are establishing a
connection between your local host and the mail server. If the
connection is established, then you must get a 220 reply from the
server. And after start with the above commands and send a mail.
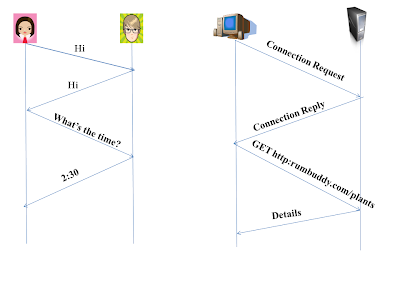
SMTP and HTTP:
HTTP and SMTP both protocols are for transfer of files from one host to
other. They both use the persistent connections and send number of files
over the same TCP connection. HTTP transfer files from server to client
and SMTP transfers mails from one mail server to other mail server.
There are some differences between HTTP and SMTP. These are:
1. On one hand where HTTP is a pull protocol. On the other hand, SMTP is a push protocol.
- HTTP is used to pull or extract the information from the server to the client. SMTP is used to push or to put the information from the sender's mail server to the receiver's mail server.
2. HTTP retrieves the data as it is in its original form only. But SMTP
requires every message to be in 7-bit ASCII format. If the message is
not in 7-bit ASCII or it is binary, then it has to be converted into
7-bit ASCII before sending over SMTP.
****** If you want to know more about Email services, I will ask you to read RFC 5321.******
I am done with the Simple mail Transfer protocol (SMTP). In the coming
post, I will tell you about one more Application Layer Protocol i.e.
Domain Name System (DNS).